Le multithreading est une technique de programmation qui permet à un programme d’exécuter plusieurs tâches simultanément au sein d’un même processus. Voici une explication détaillée du concept :
- Définition de base :
Le multithreading consiste à diviser un programme en plusieurs “threads” (fils d’exécution) qui peuvent s’exécuter concurremment. Chaque thread représente une séquence d’instructions qui peut être exécutée indépendamment des autres.
- Analogie :
Imaginez une cuisine de restaurant :
- Un chef seul (programme à thread unique) ne peut préparer qu’un plat à la fois.
- Plusieurs chefs (multithreading) peuvent travailler simultanément sur différents aspects d’un repas, augmentant ainsi l’efficacité globale.
- Fonctionnement :
- Parallélisme : Sur les processeurs multi-cœurs, les threads peuvent s’exécuter véritablement en parallèle sur différents cœurs.
- Concurrence : Même sur un seul cœur, le système d’exploitation alterne rapidement entre les threads, donnant l’illusion d’une exécution simultanée.
- Avantages :
- Performance accrue : Utilisation optimale des ressources du processeur, surtout sur les systèmes multi-cœurs.
- Réactivité améliorée : Les applications restent réactives même lors de tâches intensives.
- Efficacité : Permet d’effectuer des opérations en arrière-plan sans bloquer l’interface utilisateur.
- Défis :
- Synchronisation : Gérer l’accès concurrent aux ressources partagées pour éviter les conflits.
- Deadlocks : Situations où des threads se bloquent mutuellement, attendant des ressources.
- Complexité : Le code multithreadé peut être plus difficile à écrire, déboguer et maintenir.
- Utilisations courantes :
- Interfaces utilisateur réactives
- Traitement de données massives
- Serveurs web gérant de multiples connexions
- Applications de rendu graphique
- Implémentation en Julia :
Julia offre plusieurs outils pour le multithreading :
Threads.@threadspour paralléliser les bouclesThreads.@spawnpour créer des tâches asynchrones- Variables atomiques et verrous pour la synchronisation
- Considérations :
- Le gain de performance dépend de la nature de la tâche et du nombre de cœurs disponibles.
- Certaines tâches, comme les opérations d’entrée/sortie intensives, bénéficient moins du multithreading.
- Multithreading vs Multiprocessing :
- Multithreading : Threads partagent la mémoire au sein d’un même processus.
- Multiprocessing : Processus séparés avec mémoire isolée, communication via IPC (Inter-Process Communication).
En conclusion, le multithreading est un outil puissant pour améliorer les performances et la réactivité des applications, particulièrement adapté aux systèmes modernes multi-cœurs. Cependant, il nécessite une conception soigneuse pour éviter les pièges courants comme les conditions de course et les deadlocks.
Reprenons notre exemple précédent (avec une grille de 10 x 10) et adaptons le afin de bénéficier des apports du multithreading.
using Plots
using Base.Threads
function f(x, y)
sleep(1E-9)
return (x - 1)^2 + (y - 2)^2 - 1
end
function solve_equation_threaded(x_range, y_range, tolerance)
solutions = Vector{Tuple{Float64,Float64}}()
grid_points = Vector{Tuple{Float64,Float64}}()
# Pré-allouer les vecteurs pour chaque thread
local_solutions = [Tuple{Float64,Float64}[] for _ in 1:nthreads()]
local_grid_points = [Tuple{Float64,Float64}[] for _ in 1:nthreads()]
@threads for x in x_range
tid = threadid()
for y in y_range
push!(local_grid_points[tid], (x, y))
abs(f(x, y)) < tolerance && push!(local_solutions[tid], (x, y))
end
end
# Combiner les résultats de tous les threads
for tid in 1:nthreads()
append!(solutions, local_solutions[tid])
append!(grid_points, local_grid_points[tid])
end
return solutions, grid_points
end
# Définir les paramètres pour les tests
grid_size = 10
x_range = y_range = range(-10, 10, length=grid_size)
tolerance = 0.01
println("Number of threads: $(nthreads())")
# Test simple avec @time
println("Performance test using @time (multithreaded):")
@time solve_equation_threaded(x_range, y_range, tolerance);
# Comparaison avec la version non threadée
function solve_equation(x_range, y_range, tolerance)
solutions = Tuple{Float64,Float64}[]
grid_points = Tuple{Float64,Float64}[]
for x in x_range, y in y_range
push!(grid_points, (x, y))
abs(f(x, y)) < tolerance && push!(solutions, (x, y))
end
return solutions, grid_points
end
println("\nPerformance test using @time (single-threaded):")
@time solve_equation(x_range, y_range, tolerance);L’exécution de ce script donne ceci :
Number of threads: 1
Performance test using @time (multithreaded):
1.638399 seconds (174.92 k allocations: 8.750 MiB, 5.06% compilation time)
Performance test using @time (single-threaded):
1.556460 seconds (11.34 k allocations: 567.047 KiB, 1.02% compilation time)
Voyons l’influence de l’augmentation du nombre de threads.
Pour cela nous allons exécuter notre script Julia depuis la console (et non plus depuis VS Code) en passant le paramètre --threads
Depuis la console exécuter le script précédent
> julia --thread 2 .\solve_multithread_benchmark.jl
Number of threads: 2
Performance test using @time (multithreaded):
0.908704 seconds (205.63 k allocations: 10.362 MiB, 2.56% gc time, 18.53% compilation time)
> julia --thread 4 .\solve_multithread_benchmark.jl
Number of threads: 4
Performance test using @time (multithreaded):
0.591020 seconds (205.74 k allocations: 10.374 MiB, 2.91% gc time, 31.36% compilation time)
> julia --thread 8 .\solve_multithread_benchmark.jl
Number of threads: 8
Performance test using @time (multithreaded):
0.424595 seconds (205.94 k allocations: 10.401 MiB, 3.43% gc time, 56.25% compilation time)
> julia --thread 16 .\solve_multithread_benchmark.jl
Number of threads: 16
Performance test using @time (multithreaded):
0.275632 seconds (206.43 k allocations: 10.453 MiB, 4.45% gc time, 143.38% compilation time)
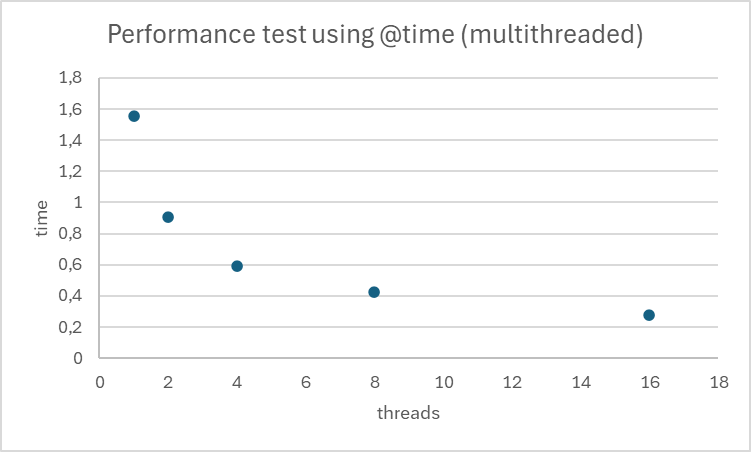 Notre implémentation montre une amélioration significative des performances avec l’augmentation du nombre de threads.
Notre implémentation montre une amélioration significative des performances avec l’augmentation du nombre de threads.
Calculons l’accélération en latence pour les différents cas étudiés précédemment. Nous la noterons par la suite speedup. C’est une mesure qui quantifie l’amélioration de la vitesse d’exécution d’un programme lorsqu’il est parallélisé, par rapport à son exécution séquentielle.
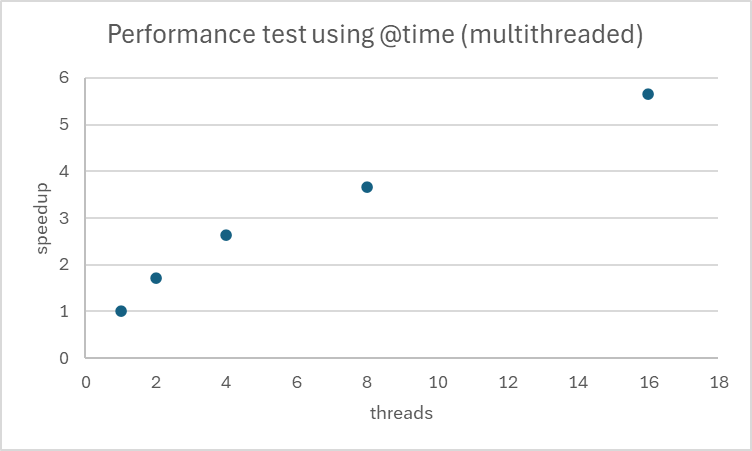
Le speedup augmente avec le nombre de threads, ce qui montre que notre code bénéficie effectivement du multithreading. Avec 16 threads, nous obtenons une accélération de 5,65x, ce qui est très bon.
La nature de notre problème semble se prêter particulièrement bien à la parallélisation. Même à 16 threads, nous continuons à voir des améliorations, suggérant que notre problème pourrait potentiellement bénéficier d’encore plus de threads.
Toutefois nous observons déjà que nous nous éloignons du speedup idéal
avec n le nombre de threads.
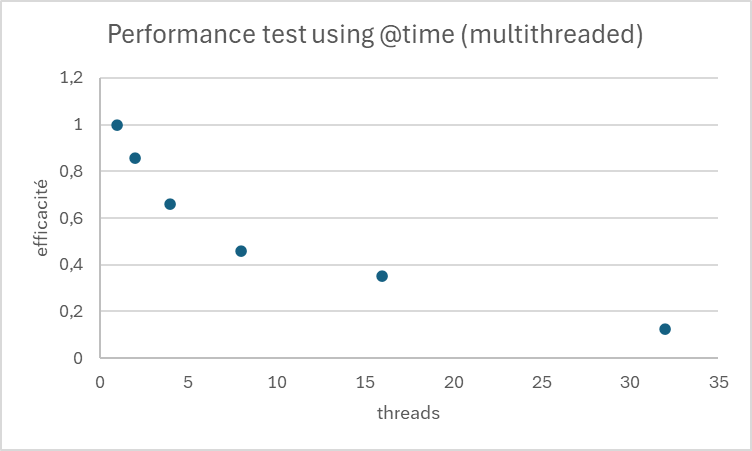
Pour évaluer l’efficacité, on peut calculer le ratio speedup / nombre de threads.
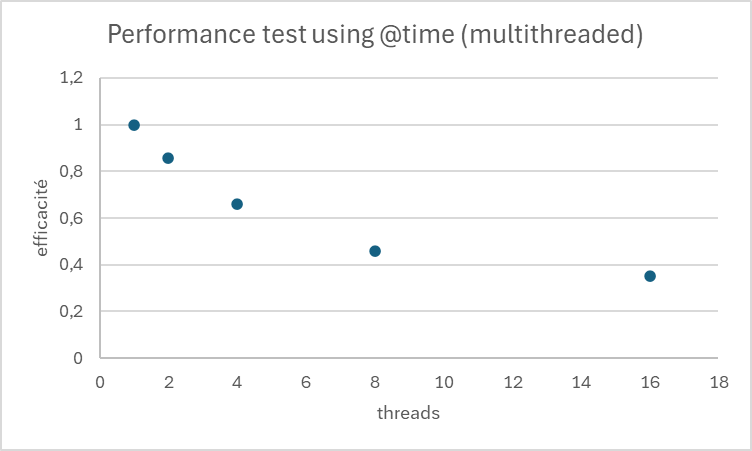
L’efficacité diminue avec l’augmentation du nombre de threads, ce qui est normal dû aux surcoûts de gestion des threads et aux parties non parallélisables du code.
Nous pourrions envisager de tester avec un nombre encore plus élevé de threads pour identifier le point de saturation pour notre problème spécifique. Il serait intéressant d’analyser les parties de notre code qui pourraient limiter la scalabilité (par exemple, des sections non parallélisables ou des goulots d’étranglement en termes de synchronisation). Nous devrions considérer la nature de notre problème : s’agit-il d’un calcul intensif, d’opérations sur des données massives, ou d’un mélange des deux ? Cela pourrait expliquer la bonne scalabilité observée. Si ce n’est pas déjà fait, nous pourrions mesurer également l’utilisation des ressources (CPU, mémoire) pour chaque configuration de threads pour une analyse plus complète.
Mais continuons sur l’analyse du temps d’exécution de notre script avec 32 threads.
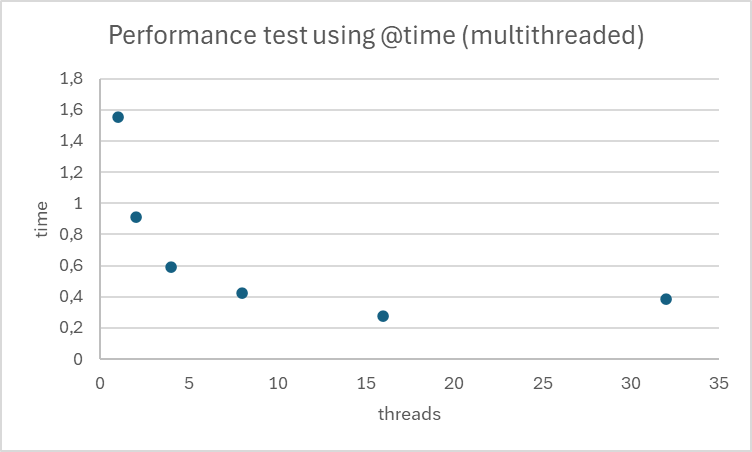
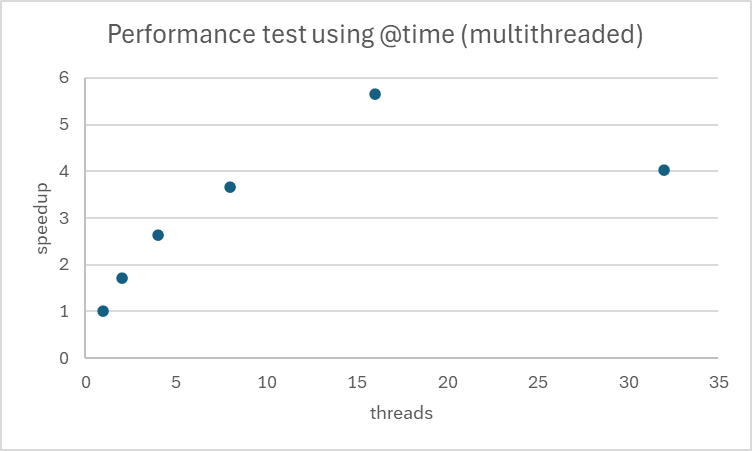
 De 1 à 16 threads, nous observons une amélioration constante du speedup, ce qui est positif. Cependant, à 32 threads, nous constatons une baisse inattendue des performances.
De 1 à 16 threads, nous observons une amélioration constante du speedup, ce qui est positif. Cependant, à 32 threads, nous constatons une baisse inattendue des performances.
Ceci s’explique probablement par l’architecture utilisée (je ne suis pas spécialiste). Le processeur est un CPU 13th Gen Intel(R) Core(TM) i7-13700K 3.40 GHz
Le 13th Gen Intel(R) Core(TM) i7-13700K est un processeur de la série Raptor Lake d’Intel, connu pour son architecture hybride. Voici les détails sur ses cœurs :
-
Configuration des cœurs :
- 8 cœurs de performance (P-cores)
- 8 cœurs d’efficacité (E-cores)
- Total : 16 cœurs physiques
-
Threads :
- Les P-cores supportent l’hyperthreading (2 threads par cœur)
- Les E-cores ne supportent pas l’hyperthreading (1 thread par cœur)
- Total : 24 threads logiques (8 P-cores x 2 threads) + (8 E-cores x 1 thread) = 24 threads
-
Caractéristiques supplémentaires :
- Fréquence de base : 3.4 GHz (comme mentionné)
- Fréquence Turbo maximale : Jusqu’à 5.4 GHz (peut varier selon les conditions)
- Cache : 30 MB Intel® Smart Cache
-
Implications pour le multithreading :
- Les 24 threads logiques permettent un haut degré de parallélisme.
- Cependant, tous les threads ne sont pas égaux en termes de performance :
- Les threads sur les P-cores sont généralement plus performants.
- Les threads sur les E-cores sont conçus pour l’efficacité énergétique et les tâches de fond.
-
Considérations pour l’optimisation :
- Les applications sensibles à la latence devraient privilégier les P-cores.
- Les tâches parallèles moins intensives peuvent bénéficier des E-cores.
- L’ordonnanceur du système d’exploitation (comme Windows 11) est optimisé pour utiliser efficacement cette architecture hybride.
En ce qui concerne nos résultats de multithreading :
- Le fait que nous ayons observé les meilleures performances avec 16 threads correspond bien à la configuration de ce processeur.
- La baisse de performance à 32 threads s’explique par le fait que nous dépassons le nombre de threads logiques disponibles (24), ce qui entraîne une surcharge de gestion des threads et potentiellement une contention des ressources.
Pour optimiser notre code sur ce processeur, nous devrions :
- Viser une parallélisation optimale pour 24 threads.
- Considérer l’utilisation d’APIs avancées qui peuvent différencier les P-cores et les E-cores pour les tâches critiques en performance.
- Être conscients que les performances peuvent varier selon la charge du système et la gestion thermique du processeur.
Cette architecture hybride offre un excellent potentiel de parallélisme, mais requiert une approche nuancée pour en tirer le meilleur parti, en particulier pour des applications de calcul intensif comme la nôtre.
| threads | time | speedup | speedup_idéal | efficacité |
|---|---|---|---|---|
| 1 | 1,55646 | 1 | 1 | 1 |
| 2 | 0,908704 | 1,71283498 | 2 | 0,85641749 |
| 4 | 0,59102 | 2,63351494 | 4 | 0,65837874 |
| 8 | 0,424595 | 3,66575207 | 8 | 0,45821901 |
| 16 | 0,275632 | 5,646877 | 16 | 0,35292981 |
| 20 | 0,283475 | 5,49064291 | 20 | 0,27453215 |
| 24 | 0,240461 | 6,4728168 | 24 | 0,2697007 |
| 28 | 0,348993 | 4,45986023 | 28 | 0,15928072 |
| 32 | 0,387461 | 4,01707527 | 32 | 0,1255336 |
| Tableau des mesures du temps de latence par nombre de threads |
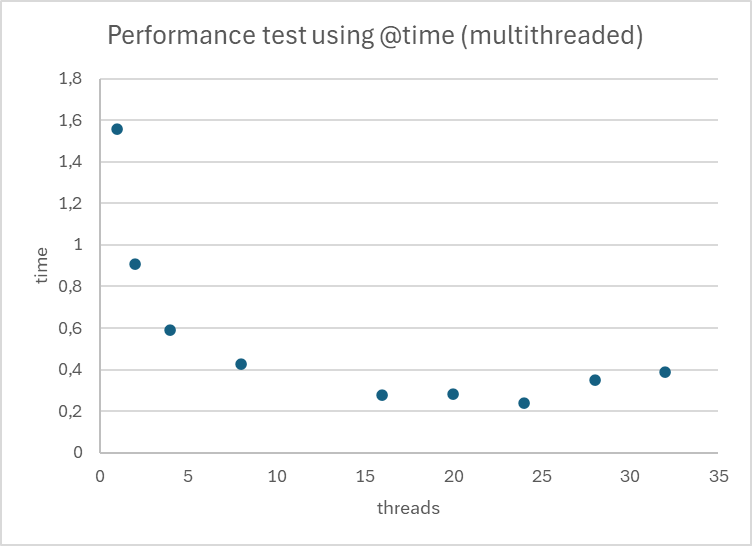
On observe un minimum du temps d’exécution du script pour 24 threads. Ce qui semble en accord avec notre connaissance de l’architecture utilisée pour cet essai.